SEC595: Applied Data Science and AI/Machine Learning for Cybersecurity Professionals
SEC595Cyber Defense, Artificial Intelligence

The latest Siftgrab update includes a new function that generates several preformatted Excel workbooks.

The latest Siftgrab update introduces a new function that generates preformatted Excel workbooks. These workbooks include pivot tables and slicers designed to isolate relationships between key fields across different artifact types. Included is a worksheet for Windows Prefetch files that simplifies the search for execution artifacts within Prefetch files. This enhancement provides a quick and efficient method to search across multiple Prefetch files.
For those unfamiliar, Windows Prefetch is a caching mechanism designed by Microsoft to optimize the performance of frequently used files. Enabled by default on Windows non-server operating systems, Prefetch files can hold extensive information about the execution of files on a system. These files are identifiable by a ".pf" extension and, since Windows 8.1, are stored in a compressed binary format with a file signature of “MAM” (4D 41 4D). By default, they are stored in the "%SystemDrive%\Windows\Prefetch" directory.
The table below highlights the different data types and key artifacts stored in Prefetch. Detailed information on Prefetch files and their structure can be found here.
Source File (NTFS) | Prefetch File | Prefetch Executable File | Volume | Load File |
Prefetch File Name | File Size | Executable File Name | Number of Volumes | Number of Load Files |
Timestamp (MAC) | Prefetch Hash | Total Run Count | Volume Name | Load File Name |
File Size | Executable File Name | Last Run Timestamp | Volume Serial Number | Load File Path |
| Prefetch file version | Previous Run Timestamps 2, 3, 4, 5, 6, 7, 8 | Volume Creation Time | Load File Order (Index) |
Figure 2 Summary of Prefetch Values
Prefetch records contain compound values and therefore there is not always a one-to-one relationship between an artifact value and a field. For example, a single Prefetch file can store up to eight different timestamps in a single field. To simplify and create searchable output, the Python script prefetchruncount.py was developed. This script flattens Prefetch results into a single CSV file. While it is part of Siftgrab, it can also be run independently on a single file or a directory containing multiple Prefetch files.
Prefetchruncounts.py performs the following tasks:
The resulting CSV output contains two different row types, each sharing three common fields. This makes it easier to compare interesting load files, paths, or executable file names against possible run times. You can also work in the other direction by comparing possible timestamps with suspicious load files or volume names by filtering common Prefetch hash values.
To further simplify the process, Siftgrab automatically applies a template to this file during execution. Additionally, the Go script csv2XLSheet and associated Excel templates can be used independently. Csv2XLSheet is particularly useful as it allows CSV files to be imported into Excel documents with pivot tables and slicers directly from the command line.
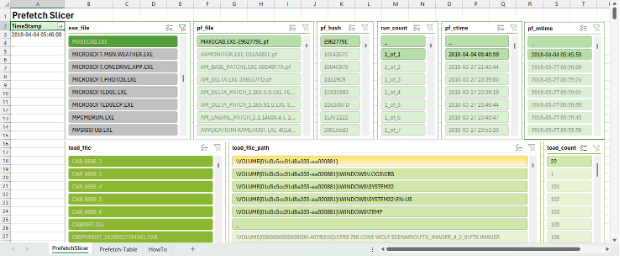
Figure 4 below contains Windows Prefetch output generated using Siftgrab. In this example, the output from prefetchruncounts.py has been applied to a custom template in the worksheet named “Prefetch-Table.” The second worksheet is a pivot table and slicer named “PrefetchSlicer.”
From the PrefetchSlicer worksheet you can filter, highlight, and identify relationships between Prefetch executables, load files, and timestamps. Slicer filters allow for single or multiple types to be selected within or across individual filters. The “TimeStamp” column is a pivot value where traditional Excel filters can be applied.
https://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blt1c08dba7ff08dffc/6761ad599628e12bc01e7b93/prefetch004.pngThe template also contains a worksheet named “HowTo,” which outlines the process used to apply Prefetch data to the template.
https://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blt498371c0da46437b/6761ad584f07d3924af40ba1/prefetch005.pngThis concept is a basic implementation of pivot tables, timestamps, and slicers, which can easily be applied to other log files and timelines. Below is an example of the entire process using a sample Apache log:
Step 1: Open a CSV log file with Excel. Select the relevant columns and format them as a table.
https://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blt0a30dcf6b2466f07/6761ad5821e066e2964125b8/prefetch006.pngStep 2: Insert a pivot table using the default values.
https://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blt3d96f7b05c1224c6/6761ad58f5804aa25fdb606a/prefetch007.pngStep 3: Set the Timestamp field as a PivotTable field and, from the PivotTable Analyze tab, select “Slicer,” checking the remaining fields.
https://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blt07fe2114c0fcb0b7/6761ad5830b280178adf6643/prefetch008.pnghttps://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blt0e10993e4da1a43c/6761ad5830b2802a71df6647/prefetch009.pngStep 4: Rearrange and customize the layout to suit your needs. If you want to reuse the layout for a certain log type, remove the data and save it as a template. For new data, you can populate it manually or from the command line using csv2XLSheet.
https://images.contentstack.io/v3/assets/blt36c2e63521272fdc/blte689fa4f9dd6bf03/6761ad59a98d651cd1cd29b7/prefetch0010.pngIn addition to Prefetch slicers, Siftgrab automatically applies slicer templates for Windows services, scheduled tasks, RDP connections, BITS, and TLN timelines. Pivot tables and slicers are useful when working with small datasets or when a SIEM or other log management solutions are not practical.
Taken one step further, you can create custom dashboards containing interactive graphs and tables by combining multiple pivot tables. The goal being to leverage Excel to segregate information into smaller, easily correlated data points or generate summary reports. Tools like csv2XLSheet can then be used to automate this process by pushing frequently used CSV output into preformatted templates.
Explore more DFIR resources and stay ahead in the ever-evolving field. Join the SANS community today to stay connected to the latest insights and innovations.
