A few days ago I wrote a post about applying the principle of least frequent occurrence to string searches in forensics. This post will discuss how long that process may take and at the end, will show some significant ways to speed up the process.
In the previous post I used the following compound command line statement to create a list of strings ordered from most frequent occurring to least frequent:
cat sda1.dd.asc | awk '{$1=""; print}' | sort | uniq -c | sort -gr > sda1.dd.asc.lfo
One thing worth noting is that the sort command is invoked twice. As you can imagine, sorting the strings from a large disk image takes time, to say nothing of doing it twice, though the second sort is much faster as it is initially sorting on the count value that uniq -c tacks onto the front of each line of text.
For example, I've got an ASCII strings file that is approximately 19GB. Below I've split out the command above and used time to measure the time required to complete each step in the process on my i7 quad-core, 64-bit Ubuntu VM with 7GB of RAM:
time cat sda1.dd.asc | awk '{$1=""; print}' | sort > sda1.dd.asc.sorted
real126m57.159s
user112m59.670s
sys10m51.150s
Running uniq against that file, again with time:
time uniq -c sda1.dd.asc.sorted > sda1.dd.asc.sorted.uniq real6m51.088s user2m4.820s sys4m45.170s
My 19GB strings file has been reduced to 2.9GB by removing duplicate lines of text. We can do better.
I can further reduce it by removing the garbage strings using the technique outlined in the previous post; namely grep and a large dictionary file. (Remember to clean up your dictionary file, no blank lines, no short strings).
time grep -iFf /usr/share/dict/american_english sda1.dd.asc.lfo > sda1.dd.asc.lfo.words real4m9.105s user3m56.350s sys0m12.250s
Now my 2.9GB strings file is 574MB.
Now we're getting somewhere, albeit slowly — not to mention the time it will take to review 574MB of text.
How can we speed this up? My initial thought was to try creating a ramdisk to see if that made things any faster. I tried that using a smaller file of course. Much to my surprise, the difference between using a ramdisk and not using one was hardly noticeable. I mentioned this on Twitter and strcpy stepped into the conversation. He's a brilliant developer whom I've talked to a few times online over the last year or so.
The next day, he sent me the following tweet:
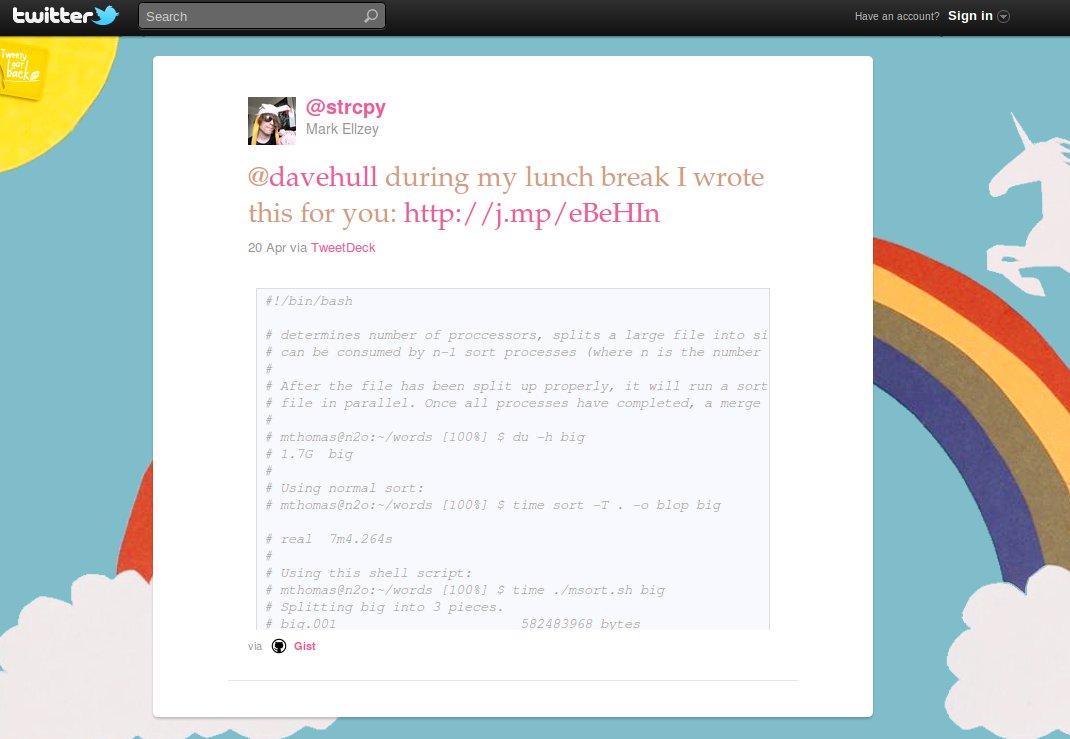
Figure 1: I owe strcpy lunch
I grabbed a copy of strcpy's script and looked it over. It was brilliant and simple and I was disappointed that I hadn't thought of it.
In a nutshell, the script counts of the number of processors in the system then divides the data set to be sorted by the number of processors minus one, then assigns each processor (minus one) with the task of sorting a chunk of the data set. It also tells the sort command how much of the system's memory it can safely use for buffering, by default sort will use 1MB, which can result in the creation of lots of temporary files (more than 1000 for my 19GB file). strcpy's script specifies 30% of RAM can be used by sort, reducing the number of temporary files used. Lastly the script merges the three sorted files back into one file.

Figure 2: System Monitor: single processor sorting
Notice that only one processor is being used for the heavy lifting of sorting the data set.

Figure 3: System Monitor: Three processors pegged
Notice that three of the four system processors are pegged, or nearly so and the amount of system memory in use has dramatically increased. Memory utilisation is configurable from within strcpy's script.
How much faster was it to run the sort this way than the previous way? Here's the output from time:
time ~/ellzey_sort.sh sda1.asc 19717183333 6572394445.0 Splitting sda1.asc into 3 pieces. sda1.asc.0016572394445 bytes sda1.asc.0026572394445 bytes sda1.asc.0036572394443 bytes Done! Running sort on sda1.asc.001 on cpu 0x00000001 Running sort on sda1.asc.002 on cpu 0x00000002 Running sort on sda1.asc.003 on cpu 0x00000004 Finalizing sort into sda1.asc.sorted Removing temporary files real72m28.051s user52m32.580s sys75m5.760s
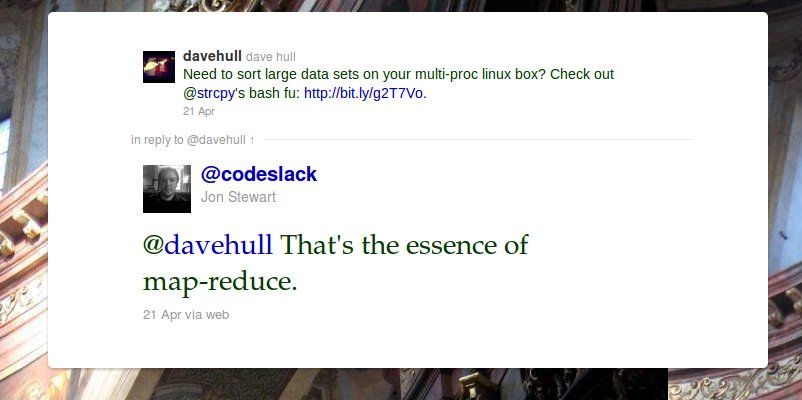
strcpy had said as much to me, "... you've been introduced to mapreduce 101."
One day in the not too distant future we'll be able to distribute these CPU intensive processes across dozens of cores.
Check out strcpy's script. It's easy to understand and can be easily modified. One thing worth noting, in my testing, the script rounded down to the nearest byte when splitting files, resulting in a loss of one byte (i.e. a 100 byte file split in three parts should be 33.33333 bytes, strcpy's script rounds this down to 33 bytes, so you'll end up losing a byte of data). I modified line 62 of the script and notifed strcpy of my change, here's what I ended up with:
... split_size=`echo "scale=10; $file_size / $proc_count" | bc | python -c "import math; print math.ceil(float(raw_input()))"` ...
This change fixes the rounding issue.
Go forth and sort across all cores.
Dave Hull is a wanna be when compared to the likes of strcpy and codeslack, but he's learning. He's an incident responder and digital forensics practitioner with Trusted Signal. He'll be teaching SANS Forensics 508: Advanced Computer Forensic Analysis and Incident Response in Baltimore, MD, May 15 - 20, 2011. If you'd like to learn powerful forensics techniques like these, sign up for the course.




