

If you've had the opportunity to take SANS 560, Network Penetration Testing and Ethical Hacking, chances are you were exposed to the Pentester's Pledge. The pledge, for those who aren't familiar is:
"I , do hereby pledge to use psexec to exploit Windows target machines after I have gained admin credentials and SMB access to the target environment. I shall forsake other service-side exploits thereafter. Otherwise, I unnecessarily risk crashing target systems".
As penetration testers, we have been endowed with the unalienable right to own all the systems (within our scope and rules of engagement of course). Cereal Killer, a whimsical character in the 1995 Hackers film, sums it up best during one of his ecclesiastical moments of clarity: "Listen, we got a higher purpose here, alright? A wake up call for the Nintendo Generation. We demand free access to data, well, it comes with some responsibility."
This responsibility is simple and it is not unique to our industry. Consider the Hippocratic Oath, which belies the medical principle of primum non nocere (do no harm). Like doctors, information security practitioners should perform with the lightest of touches. A heavy handed approach to security assessments, can lead to dire consequences side effects of pentest may include drowsy computers, frantic IT department parents, and in some cases death. Death! Yes, death, that eternal bit bucket where Google projects go to die in their hundreds. That means instead of breaking down doors with exploits, consider using the keys, after you've stolen them first of course!
In the end, though, light touches may not always be enough. When it comes to preventing a headache from escalating into a full blown migraine, vigilance is key. The sooner we can identify an unfortunate outage; the more quickly we can work with our clients to minimize any potential damage. Now, let's examine a few methods to bake rapid response actions into the penetration tester's toolkit.

Methods Covered in this Section:
Check service heartbeat:
nc -vv -z -w3 192.168.86.151
Check service every second bash loop:
while (true); do nc -vv -z -w3 10.0.0.1 80 >/dev/null && echo -e "Service is up"; sleep 1; done
Service UP/DOWN bash loop via "or":
while (true); do nc -vv -z -w3 10.0.0.1 80 2>/dev/null && echo -e SERVICE UP || echo -e SERVICE DOWN; sleep 1; done
Checking the Pulse
If the end goal is to have bash notify us the moment a service goes down, the first step is to figure out how to tell if it is up vs down. One of the easiest ways for us to check its status is to simply connect to it with a "nc". Assuming that we're planning on exploiting a target located at 192.168.86.15 on port 445, we could run the following to see that the service is still up:
Check service heartbeat:
nc -vv -z -w3 192.168.86.151 445
If the service is up we would see something like:

Command Breakdown
nc -vv -z -w3 192.168.86.151 445
1. nc - netcat is a tool that makes tcp connections given IP and PORT
2. -vv - Print output in double verbose mode
3. -z - execute in zero I/O mode. Without the -z option our nc connection to the victim machine on 445 would wait for input from the user, using the -z simply terminates the connection once it is established without sending any data.
4. -w3 - Set connect timeout to 3s
5. 192.168.86.151 145 - Destination IP PORT
While the above command could be run repeatedly (manually) to check the status of the service before, during, and after each exploitation attempt it would be easier to wrap the whole thing in one big bash while loop.
while (true); do...
Doing or checking something over and over again, endlessly sounds like a gloomy task for a person, but it suits computers just fine. Scripting languages like bash exist to help us solve a problem once and never worry about it again. The key to accomplishing this is often repetition. In computer logic, a loop allows us to do something over and over until a certain condition has been met. But what happens if we give the loop a condition that never proves true? In bash we can achieve infinite repetition like this:
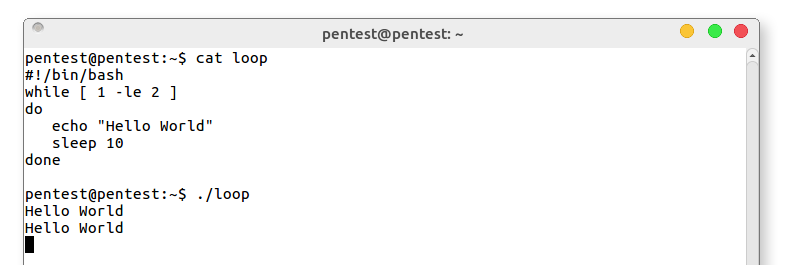
To make this more straightforward we can use something called a boolean operator. In this case, the word true will do. We can also run the entire thing on one line using the command separator: ;

Other operators we could use to build an infinite loop include: while : and while (true). Effectively, our template for running "things" is:
while true; do [thing]; [thing]; [thing]; done
Putting this all together gives us a powerful bash one-liner like this:
Check service every second bash loop:
while (true); do nc -vv -z -w3 10.0.0.1 80 >/dev/null && echo -e "Service is up"; sleep 1; done
.png)
As you can see the nc connection attempt responds with "Connection refused" as soon as the service, in this case a webserver, goes down.
Command Breakdown
while (true); do nc -vv -z -w3 10.0.0.1 80 >/dev/null && echo -e "Service is up"; sleep 1; done
1. while (true) - Begin the infinite loop
2. do nc -vv -z -w3 10.0.0.1 80 - Check service status
3. >/dev/null && echo -e - Suppress connection output and echo success to stdout
4. sleep 1 - Pause for 1 second before moving on
5. done - Finish the loop, and start back at the beginning
Success && || (and/or) Failure
For cleaner output we could suppress the output of the connection test and echo status messages based off of whether the last command was successful. Adding on the || (OR) operator allows us to make the service respond in a customizable fashion when the connection is refused:
Service UP/DOWN bash loop via OR:
while (true); do nc -vv -z -w3 10.0.0.1 80 2>/dev/null && echo -e SERVICE UP || echo -e SERVICE DOWN; sleep 1; done

Command Breakdown
while (true); do nc -vv -z -w3 localhost 80 2>/dev/null && echo -e SERVICE UP || echo -e SERVICE DOWN; sleep 1; done
1. while (true)...SERVICE UP - See previous command breakdown
2. do nc -vv -z -w3 10.0.0.1 80 - Check service status
3. || - The && operator means: "run the following if the previous executed successfully" || executes if it did not (connection refused)
Bonus - Leveraging the Environment
What if checking a service's status is not as simple as port UP/DOWN? Emily Cole (@unixgeekem) has some additional advice on the subject. Specifically, leverage the environment to gather additional telemetry on what may be going on. Techniques like "tail -f" against server logs or direct monitoring of syslogs and SEIM data can provide extra situational awareness. Occasionally, you may already have this access through past exploitation, but in the case of highly sensitive or production systems consider working with the host organization to have this access included in the rules of engagement up front. This might feel like giving away the keys, but remember: primum non nocere.
Matthew Toussain
https://twitter.com/0sm0s1z

