

According to Verizon's 2016 Data Breach Investigations Report 30 percent of phishing messages get opened by targeted users and 12 percent of those users click on the malicious attachment or link. That means, on average, every 4 phished users should (statistically) yield one click. Developing a highly targeted message and leveraging additional backend resources to validate the message's legitimacy can go a long way to raising those odds even further. In many cases the first step to establishing this "legitimacy" I developing a web presence. Having a believable page to redirect users is a key component to maximizing success. While there are robust methods and frameworks for doing so, the Social Engineering Toolkit being a community favorite, sometimes a quick and dirty command line clone is enough to get the job done. When this is the case the "wget" command has options to crawl and retrieve a website's page hierarchy.
Methods Covered in this Section:
Checking and starting the Apache Web Server:
systemctl status and systemctl start
Cloning a target website:
wget -r -nH $URL
Cloning a target webpage:
wget -r -np $URL
For this example, we'll assume that our target organization is involved in workplace automation. With that in mind we do a little research and find a recently published article with the headline "Half the work people do can be automated".
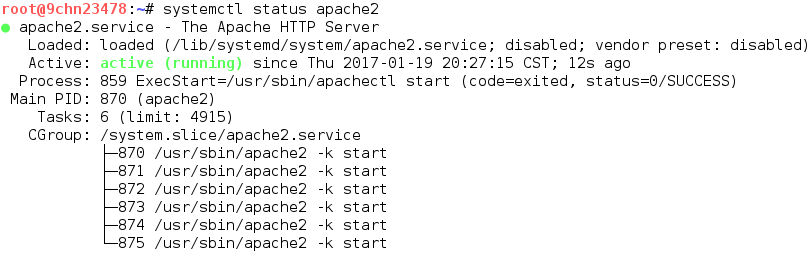
To host the site, we plan on cloning we need to use a web server. Popular options include Apache, Nginx, IIS, and Tomcat. As apache2 ships with Kali Linux we'll use that. On Kali, we can check the webserver's status by using the systemctl command. By default, apache will not start on boot so our command output should look a little something like:
Checking the webserver status

Issuing a "systemctl start apache2" command activates the webserver. The start command won't display any output if it is successful. We can verify that Apache is running with the "systemctl status apache2" command. This time the output should show the status as active (running).
Checking if our webserver is running (again)
Now that our server is up, we just need to clone our site and move it to the document root of the default website. This is the folder that a webserver uses to distribute content upon receipt of a web request. Since this location can vary depending on apache version and distribution, it may be necessary to verify the location by examining the current Apache configuration. Depending on the Apache setup this information will most likely be in either "/etc/httpd/conf/httpd.conf" or "/etc/apache2/sites-enabled/000-default.conf" by default. On the Kali distribution used here the latter option was valid. The grep command provides a succinct mechanism to validate the DocumentRoot configuration:

The server is now running and we have identified where to put the mirrored website. The final step is to clone our target site using the "wget" command. Using our target as the URL:
Cloning the website
wget -r -np <url here>
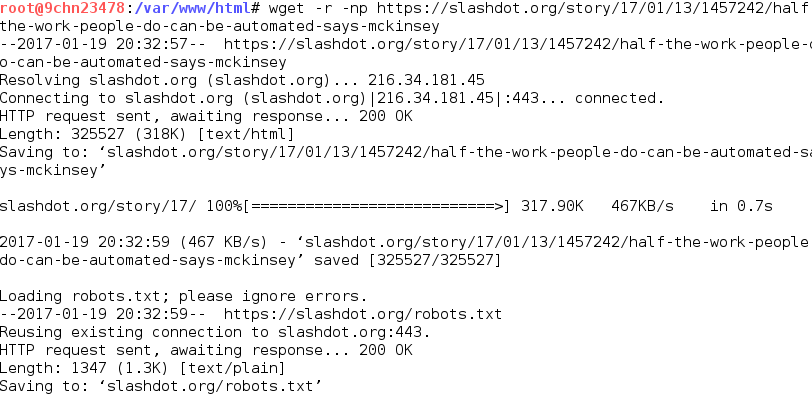
The flags in the above command tell "wget" to recursively (-r) fetch resources and to avoid fetching anything at the parent directory or above except for explicitly listed links (-np). Recursive fetching ensures that all referenced resources are downloaded and the no parent option prevents the retrieval of resources above the targeted site in the directory hierarchy. The no-host-directories (-nH) option can be used to cut out the host prefix. Essentially this causes the directory structure to be created relative to the cloned copy. After running the "wget" command multiple resources will be downloaded and eventually we'll get a finished message telling us how many files were downloaded and the total size of the download. In order to finally host the content we just have to move all the downloaded files to the DocumentRoot that we determined earlier.
That's it! At this point there is a cloned website being hosted on our Kali station ready for use as a landing site to point our phishing victims to. Now we can freely edit the page, maybe to inject content we want to execute in the victim's browser, or check our apache logs to see what public IPs connected from our phishing attempt.

Best of luck on your phishing trip!
Matthew Toussain
https://twitter.com/0sm0s1z

