
Authors: Chris Dale (@ChrisADale) and Vegar Linge Haaland (@vegarlh) created this post to bring awareness to the dangers of using URL shortening services. They both work at Netsecurity, a company which serves a multitude of customers, internationally, with services within networking, security operations, IR and Penetration Testing.
URL shortening services are common use for many today. They allow you to create convenient short URL's that serves as a redirect to otherwise long and complex URLs. Such a shortened URL can look like this: https://bit.ly/2vmdGv8 . Once clicked, you will be immediately redirect to whichever URL bit.ly has stored behind the magic value of 2vmdGv8. A team from archiveteam.org, called URLTeam, has taken on the task of discovering what secrets these magic values hold.
URLTeam's mission is to take these shortening services, i.e. https://bit.ly, https://tinyurl.com, and bruteforce the possible values they can hold for their magic values. Currently the team is working across a bunch of shortening services, all of which can be found here: https://www.archiveteam.org/index.php?title=URLTeam#URL_shorteners, currently about a 130 different services supported. Their efforts effectively reveal the destination redirect of the magic values, and we can very quickly find juicy information!
Some of the information one can find are e.g. URLs pointing to file shares otherwise un-discoverable, links to testing and staging systems and even some "attack-in-progress" URL's where we can see attacks against target systems. For penetration testers, searching through the bruteforced results might be a helpful addition to the reconnaissance process, as it might reveal endpoints and systems which would have previously gone undiscovered..
This blog post describes how to set yourself up with a setup for easy searching through this amazing set of data. That's what we got for you in this post. First, some analysis of the data available, and then some quick and dirty setup descriptions to make this amazing data-set available for yourself.
Revealing secrets
Let's take a look at what type of sensitive, funny and otherwise interesting information we can find in URL shortener data. Below are some examples of the things we found by just casually searching, and utilizing Google Hacking Database (https://www.exploit-db.com/google-hacking-database/) type of searches. We have tried to redac the domain names in question in order to protect the companies vulnerable.
Hack in-progress
First out is the "Hack In-Progress" type of URLs. I am guessing black-hats, and perhaps others too, are using these to share their work in progress with their peers. Some of the identified URLs seem to be simple Proof-Of-Concepts, while others are designed for data exfiltration.
Below we see attacks trying to exploit a Local File Inclusion (LFI) by including the Linux file /proc/self/environ. This file is commonly abused to try get a shell from having found a LFI vulnerability.
| Search term | Example data |
| {"wildcard": {"uri_param.keyword": "*/proc/self/environ"}} |  |
Then we can see some further expansions on the LFI vulnerabilities, using a Nullbyte (%00) to abuse string terminations, a common vulnerability on e.g. older PHP installations.
| Search term | Example data |
| {"wildcard":{"uri_param.keyword":"*%00"}} | 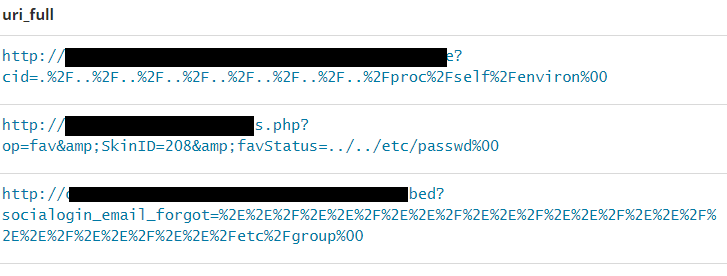 |
We also see attacks containing carriage-return (%0D) and line-feeds (%0A). In this example we see an attempted command injection, trying to ping the localhost 5 times. The attacker will measure the time taken from a normal request, i.e. without attack payload in it, vs. the request below. If the time taken for the request to complete is approximately 5 seconds higher using the attack, it confirms the attack vector and a command injection is very likely to be possible.
| Search term | Example data |
| {"wildcard":{"uri_param.keyword":"*%0a"}} | 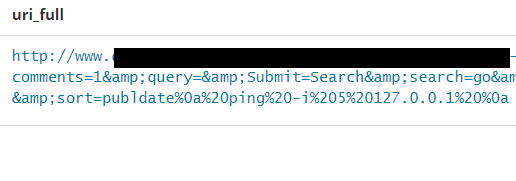 |
And finally, of course, SQL Injection queries.
| Search term | Example data |
| "Union all" |  |
Backup data
Next up in line of examples is backed up data. Many developers and IT-operators make temporary backups available online. While sharing these, it is evident that some of them have used URL shorteners to make life more convenient. This vulnerability classifies as a information leak.
| Search term | Example data |
| {"wildcard": {"uri_path.keyword": "*.bak"}} | 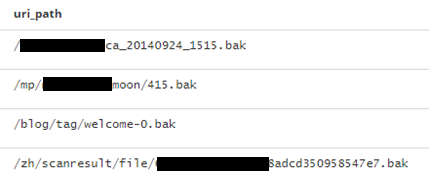 |
| {"wildcard":{"uri_path.keyword":"*.sql"}} | 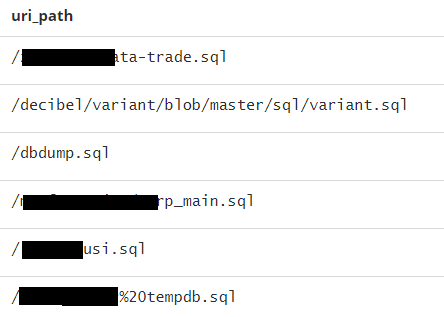 |
File sharing
Another common finding is people sharing files with no password protection, assuming that the random identifiers (magic values) will keep the documents safe. But when they use URL shortener they effectively share the URL with the world. In this case we're looking for Google Documents, and honestly there is so many sensitive documents leaked here, across a plethora of different file sharing services.
| Search term | Example data |
| uri_domain:docs.google.com | 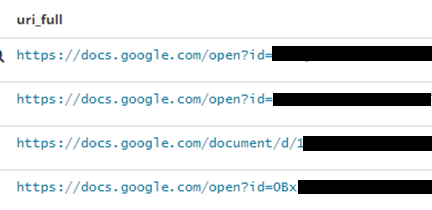 |
| uri_main_domain.keyword:mega.nz |  |
| uri_main_domain.keyword:1drv.ms |  |
Booking reservations and similar
Cloud storage links are not the only passwordless links that are being shared online. Hotel and travel ticket systems also commonly send you emails with passwordless links for easy access to your booking details, as handily provided below:
| Search term | Example data |
| uri_domain:click.mail.hotels.com |  |
Test, Staging and Development environments
There are also a lot of test systems being deployed, and links are often shared between developers. Searching for test, beta, development etc. often reveal some interesting results as well.
| Search term | Example data |
| uri_lastsub_domain:test | 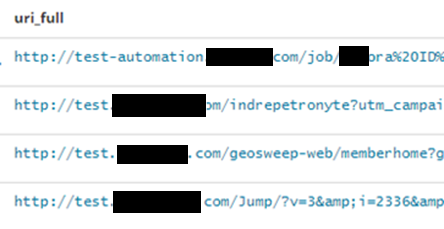 |
| uri_lastsub_domain.keyword:staging | 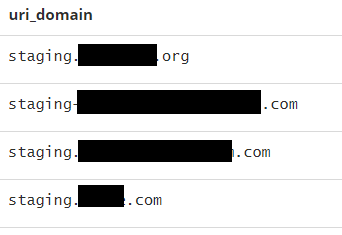 |
Login tokens and passwords
Session tokens in URL's have for years been considered as a bad practice, primarily because proxies and shoulder surfing attacks could potentially compromise your current session. In the dataset there were many examples of URL's containing sensitive info, e.g tokens and passwords.
| Search parameter | Example data |
| {"wildcard":{"uri_param.keyword":"*password=*"}} | 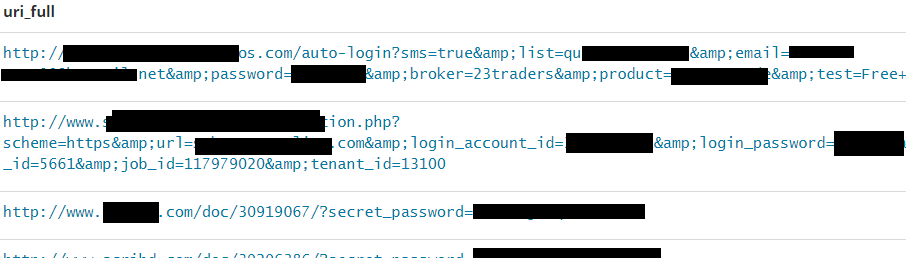 |
| {"wildcard":{"uri_param.keyword":"*jsessionid=*"}} | 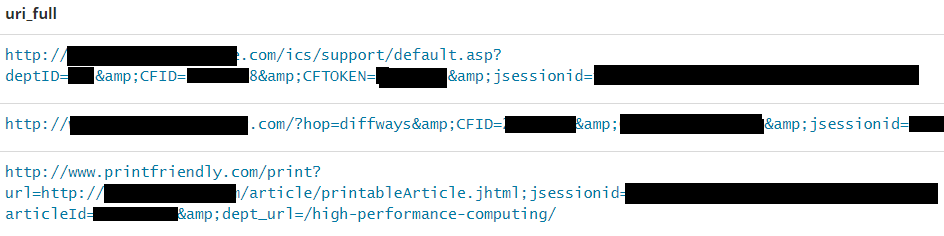 |
Conclusions
By looking at the archiveteam.org's data it is very evident that sensitive data is being shortened unscrupulously. It is definite that these services are being used without properly thinking through who else can gain access to the URLs, a classic example of security through obscurity. Obviously, someone with bad intentions could abuse this to their advantage, but it is also clear that organizations could utilize these same services to look for their own data being leaked, and possibly compromised. Furthermore, penetration testers could use these techniques to look for their customer data, providing potential valuable intelligence into attack surface they could work on.
What type of vulnerabilities and information leaks can you find? Please share in the comments below. In the next section we share how to get this setup running on your own server, so you can start analyzing and protecting yourself.
Setup and Installation
A detailed description of the configuration in use would probably require it's own article so to avoid making this one too long we will not go deep into the configuration in details but we will give a brief description of the components in use.
Our current setup involves two servers. One OpenBSD server which is used for fetching files and sending them to the database server, relaying https requests, and another running an ELK (Elasticsearch / Logstash / Kibana) stack. The ELK stack is running on FreeBSD with ZFS. It is composed of the following components:
- Elasticsearch: The database.
- Logstash: Log and data-parser. Parses the data to a common format and feeds it into Elasticsearch.
- Kibana: A web server and frontend for Elasticsearch.
Setting up these services are a common practice today, and there exists a multitude of tutorials on how to accomplish this today.
On the OpenBSD server we have a script for downloading archives from archive.org. Files are decompressed and content is appended to a file which is monitored by Filebeat. Filebeat then sends the data to Logstash on the server which is running on the Elasticsearch server. Logstash is set up with some custom grok filters which splits up the URLs into separate fields. We created some handy fields to use for filtering and graphs. Logstash then sends the processed data to elasticsearch. The data is stored in indices based on their top domain (.com .org .no etc). This is done to speed up searches for specific top level domains. Below you can see the fields we have extracted from the URLs.


